Analyzing Wikipedia browsing history
Publication date: 24 Mar 2019 (last updated: 18 Oct 2023)
Since November 2017, Wikipedia has been regularly releasing monthly clickstream data. This data captures the summarized page-to-page user visits to Wikipedia articles. It is a record of how the world browses Wikipedia.
The Wikipedia clickstream datasets consist of aggregated records of clickstream events. A clickstream event occurs when a user goes from one webpage to another. In the data, it is recorded as a data row containing the source webpage, called a referer, the destination webpage, called a resource, the type of the reference, and the total count of times users went from the referer to the reference in a given month.
To maintain user privacy, the clickstream events are added up across all users for the given month, and those of them that add up to less than 10 are dropped from the datasets. This means that there is no individual user information in this data, and that clickstream events that are so rare that they could potentially uniquely identify users have been removed. In addition, the publishers of the data do their best to filter any known spider traffic out of it.
Here are a couple of sample Wikipedia clickstream data rows:
| referer | resource | reference type | count |
|---|---|---|---|
| Suki_Waterhouse | List_of_Divergent_characters | link | 86 |
| other-internal | Bureau_of_Investigative_Journalism | external | 18 |
We can only see the exact webpages of Wikipedia articles in the data. Pages that are not Wikipedia articles are recorded as general categories, like the referer in the second sample data row above.
The resulting clickstream data is an anonymized version of our collective browsing history on Wikipedia, released in monthly batches. We can use data science techniques to explore it.
So, let’s see what we’ve been up to on Wikipedia in December 2018.
Why December 2018? These monthly clickstream datasets are very large and can take a long time to process, so for practical purposes, we’ll analyze just one month’s worth of the data. I’ve picked December 2018 because it was the most recent month available when I started working on this side project, but the same analyses can be done on any of the available English Wikipedia datasets (and with adjustments for language differences, for the several non-English language Wikipedia clickstream datasets available).
What did we do on Wikipedia?
As of March 24th 2019, there are 6.88 billion clickstream events in the Wikipedia clickstream data for December 2018, reaching about 5.2 million unique Wikipedia articles, or about 90% of the 5.8 million Wikipedia articles in existence at the time. The clickstream data has been cut off to a traffic minimum of 10, so each of those 5.2 million articles was visited at least 10 times, and the 6.88 billion clickstream events in the dataset make up about 90% of the total 7.67 billion user clickstream events to English Wikipedia in December 2018 (source (updated link)).
To see where much of this traffic went, we can check Wikipedia’s Topviews Analysis tool for December 2018 top article views stats:
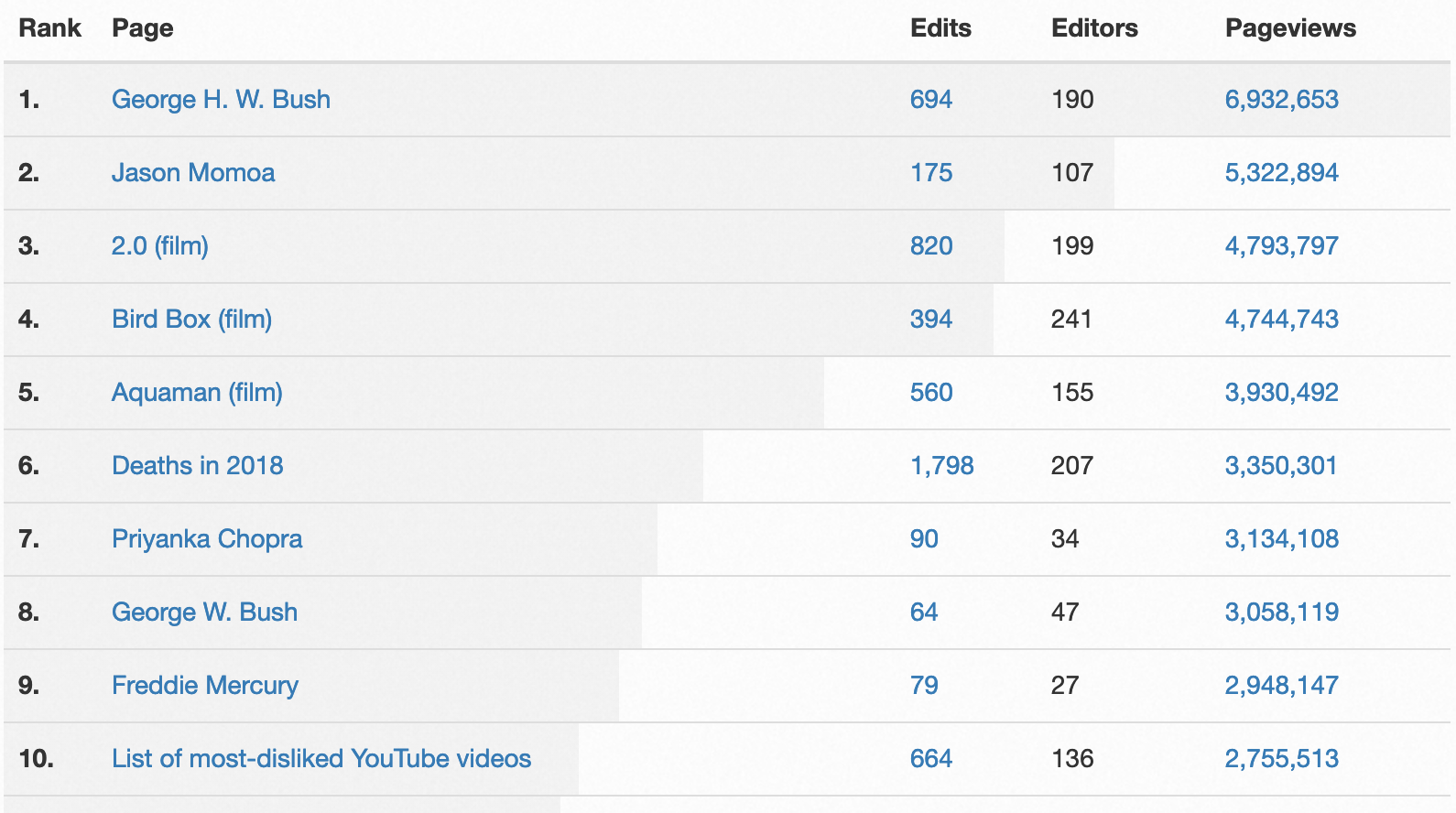 Source: Wikipedia’s Topviews Analysis tool
Source: Wikipedia’s Topviews Analysis tool
The top viewed Wikipedia articles in December 2018 were mostly about recently released movies and famous people. The #1 most viewed article was about George H. W. Bush, who died on November 30, 2018.
We can use the Wikipedia clickstream data to drill down further into our Wikipedia browsing history. If we split the Wikipedia article views by traffic type, we can roughly see how people got to the article pages.
The visualization below is interactive. Click on a traffic type to see its stats.
Note: the traffic counts here are slightly lower than those from Wikipedia’s Topviews Analysis tool. This difference is likely due to the traffic minimum cutoff.
The breakdown of Wikipedia article views by traffic type shows that about 40% of the time we got to Wikipedia articles from online search results, and we’ve searched for nearly 60% of all English Wikipedia articles that were in existence as of December 2018. That’s impressive, but not as impressive as the empty referer traffic, which has visited nearly 90% of the existing articles.
Empty referer traffic could result from several scenarios, including entering the website URL into the browser address bar, opening a bookmarked webpage, setting a webpage as the browser’s default page, various security measures, spiders and other automated browsing, etc. (see this discussion on StackOverflow for more details). About half a billion, or 27%, of the 1.8 billion empty referer traffic went to the Wikipedia Main Page article, which seems like a good candidate for bookmarking, setting the page as browser default, or typing the page URL into the browser address bar. The rest of the empty referer traffic is thinly spread across the 90% of existing articles, with less than 1% of the empty referer traffic going to any one article. The wide reach of this remaining empty referer traffic is probably the result of automated article visits by spiders and bots.
The next big chunk of our online traffic to Wikipedia articles comes from the Wikipedia articles themselves. About 25% of the December 2018 traffic to Wikipedia articles consisted of users clicking on a link in a Wikipedia article to go to another Wikipedia article. Another 0.9% of the traffic was from users going from one Wikipedia article to another, but with no link from the former to the latter. According to the Wikipedia clickstream data’s documentation, this could happen when users search from a Wikipedia article’s page, or if they spoof their referer. For simplicity, we’ll assume that these clickstream events are internal searches from Wikipedia article pages. Putting the links traffic and internal searches together, we see that 25.9% of Wikipedia traffic in December 2018 happened because people went from one Wikipedia article to another and kept on reading.
Where did we go when we kept on reading?
Let’s now focus on just the links and internal searches traffic. The data records for that traffic consist of article-to-article clickstream hops, and if we join them all together, we get a network (a.k.a. a graph) of Wikipedia articles connected by the user traffic between them. We can then use graph/network analytics to see if there are any interesting patterns in these article-to-article connections. This way we can explore how we browse Wikipedia and where we tend to go when we follow Wikipedia article links or search for more content to read.

Click here for a higher resolution version of this graph visualization (with article titles).
The colors in the graph represent clusters of articles grouped by traffic connections. These article clusters were identified using the Louvain community detection algorithm in neo4j, which has found 1,698 clusters. A group of articles forms such a cluster if the articles in this group have more and stronger connections among each other than with the rest of the network. The strength of these connections is measured by the amount of traffic going between the articles.
The hairball graph visualization above does a great job at illustrating just how complex our browsing behaviors are, but it’s very hard to see what’s going on inside it. To clean up the hairball, we can group the article clusters, a.k.a. communities, into article community nodes, and sum up the article-to-article traffic into community-to-community traffic.
In the high-res version of the article-to-article graph above, we can look around an article community and get a sense of what it is about by reading the article titles. When grouping the article communities into community nodes, we lose that ability to see the individual article titles within a community, which makes it hard to tell what the article communities are about. To remedy that, we’ll use natural language processing techniques to extract key terms from the article titles within communities. We can use a technique called bag-of-words to extract the top 10 most frequent lemmatized words used in article titles within each community. These lists of top 10 words for each article community can give us a rough idea of what each community is about. We’ll also use a technique called named entity recognition to extract the top 5 named entities for each community. This will tell us whether an article community mostly contains articles about people, places, organizations, or something else.
The result is the article community-to-community graph shown in the visualization below. It is still a hairball of sorts, but it is now much easier to navigate. And since the aggregated communities are less complex to visualize, we can display all 1,698 of them.
The visualization below is interactive. Click the “Show legend” button for more information about the visualization notation. Zoom in, drag the article community nodes around, or click on one of them to see its community stats card.
At the bottom of each community stats card are listings of the top 5 most significant articles in the community, organized into tabs by the following metrics: top viewed articles, influencers and connectors. Click on the tabs to see them.
Click here for a full page version of this visualization.
Visualizing our Wikipedia browsing history this way, we can see some patterns emerge.
There are 7 major article communities that can be roughly described by the following topics:
Community id 3: current events, politics and famous people relevant to the United States
Community id 7: religion, literature, history and culture
Community id 4: movies, tv and actors
Community id 10: the United States
Community id 5: music, musicians and discographies
Community id 1: software and tech
Community id 2: health, biology and sexuality
You can look up these article communities by plugging their ids into the search box in the visualization above.
The 7 largest article communities above cover the topics one would expect to see, but if we take a look at the smaller communities, the topics get a bit more interesting. Towards the bottom of the graph visualization, we have a cluster of medium-sized communities, which seem to have lots of search traffic between each other. Many of them are focused on specific sports, hobbies and interests. For example, we’ve got a wrestling/boxing community (id 15), a chess community (id 20), a Tolkien community (id 46), an Indian movies community (id 9), a trains community (id 0), and so on. And then we have a big cloud of very small article communities, where each focuses on a very narrow topic, like a specific book or event.
An interesting feature of the topics of these article communities is that many of them are combinations of multiple themes, and many topic words span multiple communities. For example, while community 7 is a combination of religion, literature, history and culture, the topic terms related to literature are also spread out across many other article communities.
To explore these community topic patterns a little further, we can search the article community topics for specific terms and highlight the communities that match.
Let’s start with everyone’s favorite topic.
Politics
 Communities found: 202
Communities found: 202
politic || elect || govern || diplomat || presid || feder || parliament || mayor || gubernatori || senat
The pink circle highlights show article communities that match the chosen topic terms.Many of the small politics-themed communities are about local elections around the world. Those of them located to the bottom left of the largest politics node are mainly about North American local elections.
These highlights illustrate in broad strokes the complexity of topics we read about on Wikipedia. They are not meant to precisely show a topic term distribution. Doing so would call for a more in-depth NLP analysis and a more precise topic term matching.
The visualization above shows not the quantity of politics-themed articles read on Wikipedia, but rather the spread of the topic of politics across both a very large and highly interconnected article community and a multitude of very small and isolated communities.
For a closer look, here is the interactive communities graph visualization with a highlighting search. To highlight the communities with political topics, copy the topic terms selection listed under the politics graph visualization above, and paste it into the highlighter prompt.
You can also try highlighting your own topic terms in the graph. Just make sure to read the highlighter search prompt instructions.
Let’s try highlighting a few more popular topic terms.
Movies vs TV
Movies
 Communities found: 90
Communities found: 90
TV
 Communities found: 37
Communities found: 37
Some ethnicities have unique movie/TV article communities: for example, an Indian movies/TV community (id 9), and a Chinese and South Korean movies/TV community (id 17).
Music and books
Music
 Communities found: 147
Communities found: 147
music || song || singer || discograph
Books
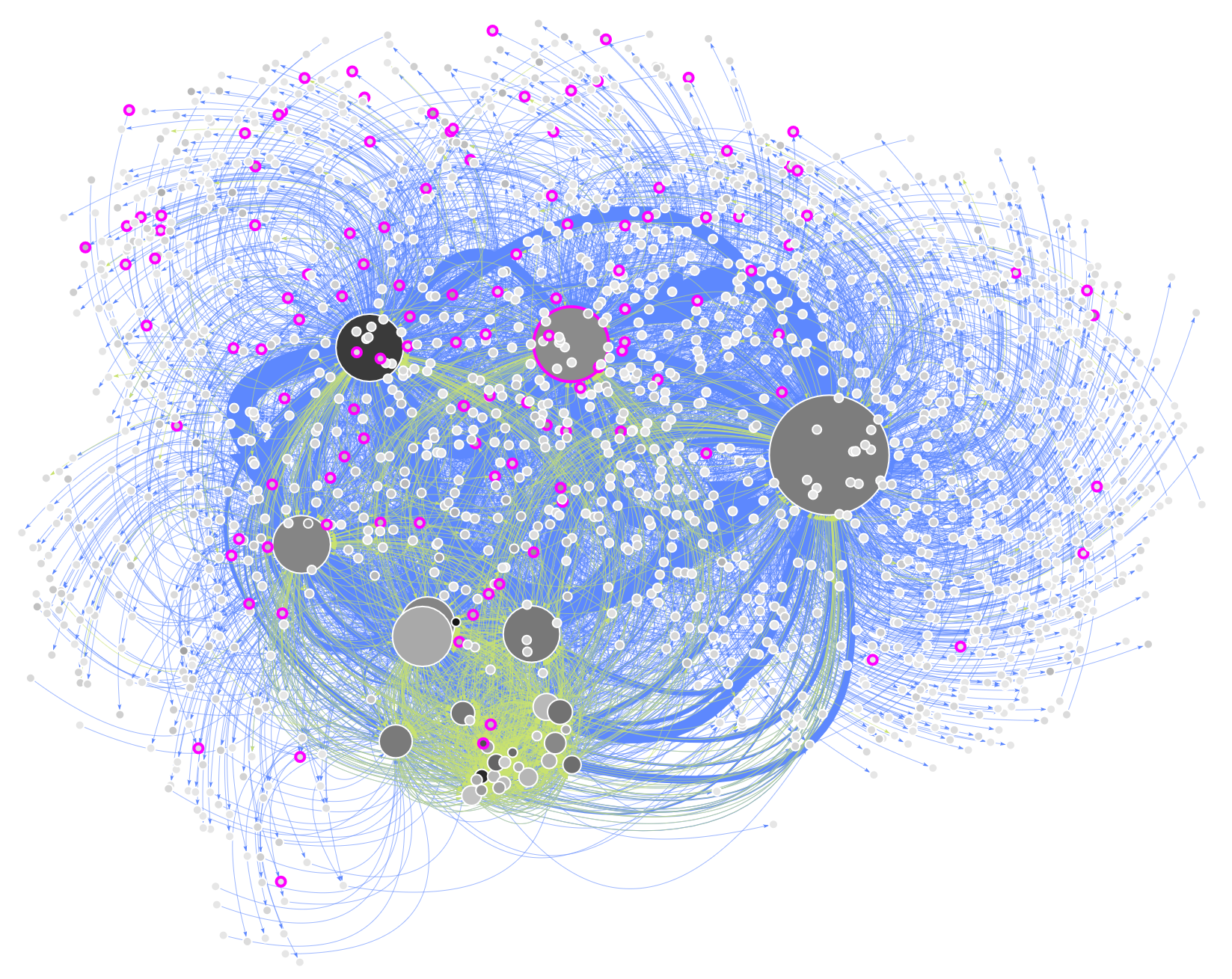 Communities found: 121
Communities found: 121
novel || book || literatur || author || writer
Both music and literature Wikipedia browsing appears to be more niche. These topics are more spread out across the small and more isolated communities. The large communities that have them as key topics are not as highly interconnected as the large movies-themed community.
Sports
There are lots of sports-themed article communities of all sizes. The most popular sports topic is football, including both American football and soccer. It is very difficult to separate the two, since both can be called football. A somewhat successful attempt to separate them out is shown in the highlighted graphs below.
All sports
 Communities found: 85
Communities found: 85
sport || olympi || champion || athlet || team || swim || runn || footbal || soccer || basketbal || basebal || hockey || wrestl || tennis || golf || cricket || rugbi
American football
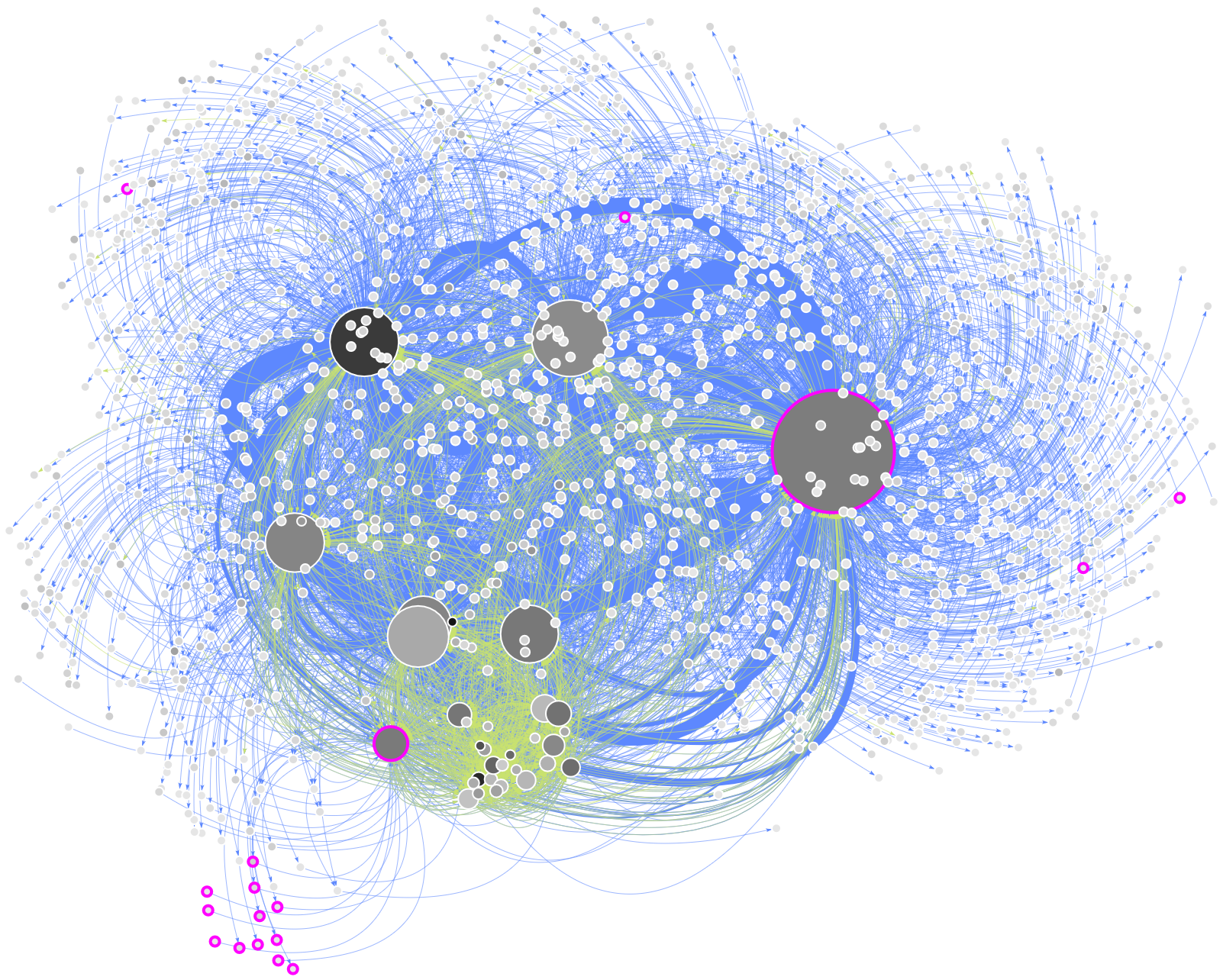 Communities found: 18
Communities found: 18
(footbal && team && !(nation)) || (footbal && (america || (unit && state) ))
Soccer
 Communities found: 31
Communities found: 31
soccer || (associ && footbal) || futebol || (footbal && !( (footbal && team && !(nation)) || (footbal && (america || (unit && state) )) ) )
John vs Mary & Co.
Looking through the article community topics, it’s easy to notice that many of the top 10 topic words have the name John in them. The name John is probably not a trending topic all by itself. The most likely reason it shows up in the top 10 topic terms for so many communities is because these communities have articles about notable people, many of whom happen to be named John.
Just John
 Communities found: 73
Communities found: 73
Mary, Maria, Anna, Anne, Elizabeth, etc.
 Communities found: 48
Communities found: 48
(mari && !(mariag || marin)) || anna || (anne && !(channel || branne || gannet)) || elizabeth
For comparison, let's also highlight some popular English-language female names. The highlighting on the left shows matches for Mary, Maria, Anna, Anne, Elizabeth, as well as any names that contain these names, i.e., Rosemary, Hannah and Annette are also included in that highlighting.
These name distributions across the article communities illustrate the gender disparity in our Wikipedia browsing experience. This gender disparity is probably in large part due to the gender inequality of the underlying biographical content on Wikipedia. Gender bias is a frequent criticism of Wikipedia, and finding evidence of it in the Wikipedia clickstream data is not surprising.
In a 2016 paper by Wagner et al., the authors found evidence of a higher notability standard for articles about women on Wikipedia. This means that fewer women are considered notable enough to have a biographical Wikipedia article written about them. The authors also found structural differences between hyperlinks in articles about men and women. The paper points out that while some of these differences are due to historical and social contexts, others are attributable to Wikipedia editors.
These biased differences in content and link structures of the articles are bound to constrain our browsing behaviors to reflect and further propagate these biases. But it is also probable that on top of the biases in the underlying content, we intentionally or unintentionally choose to read articles about men more often. If that’s the case, then we may have a feedback loop, where articles that are about men get read more often, which leads to more edits, which leads to improved content and more hyperlinks, which leads to those articles being read more, and so on.
The John vs Mary & Co. name distributions above cannot tell us whether the gender differences we see in our Wikipedia browsing history are strictly due to the biases in the underlying content, or if our browsing choices are also responsible. But they suggest that the Wikipedia clickstream datasets can be useful for further research of gender biases on Wikipedia. It would be interesting to see what happens to the gender biases in our Wikipedia browsing history after we control for the biases in the underlying content.
Summary of findings
Here’s what we’ve learned about our Wikipedia browsing history for December 2018 from the analyses above.
About 60% of the time we got to Wikipedia from search engine results, reaching nearly 60% of all English Wikipedia articles in existence at the time. And about 10% of the time we probably got to Wikipedia by following a bookmark to Wikipedia’s main page, or something similar. It is hard to say anything definite about the remaining 30% of our traffic to Wikipedia in that month.
After we got to Wikipedia, less than a third of the time we went on to read more articles, mostly by following links and occasionally by searching for more content.
When we did keep on reading, our article browsing behaviors formed a complex hairball of a network, with some interesting patterns. Those patterns group the Wikipedia articles we’ve visited into article communities, with discernible community topics and unique statistics.
These article communities show that our browsing history had 7 main themes, roughly summed up as:
1) current events, politics and famous people relevant to the United States
2) religion, literature, history and culture
3) movies, tv and actors
4) the United States
5) music, musicians and discographies
6) software and tech
7) health, biology and sexuality
Beyond the 7 main themes above, a few dozen smaller but still sizable article communities reveal more niche browsing interests, including various sports, mountaineering, trains, airplanes, Indian movies, Tolkien, chess, Eurovision, and so on. Further, a big cloud of tiny article communities, with each focusing on a very narrow topic, like a specific book, person or event, shows that our browsing history also contained many unique and somewhat isolated research efforts.
An interesting feature of these article communities is that they’ve formed around complex intersections and overlaps of topics (which can be seen when we search for common topic terms across all article communities in the interactive visualizations above).
While analyzing the Wikipedia clickstream data we’ve stumbled upon evidence of gender bias captured by the data. According to our Wikipedia browsing history, in December 2018 we’ve read a lot more articles about Johns than about Marys, Marias, Annas, Annes, Elizabeths, etc. combined.
Reference
- The Wikipedia clickstream datasets are available for download here, along with their accompanying documentation
- All data wrangling, analyses and visualizations code is available on github: Wikipedia clickstream graph project